OpenCode 入门与使用笔记
OpenCode 是一个开源的 AI coding agent。官方一句话说得很直白:它可以跑在终端、桌面端或者 IDE 里,帮你理解代码、修改文件、执行命令和处理多步任务。
如果只把它理解成“会聊天的命令行”,那多少有点委屈它了。更准确一点说,它像是一个愿意进你项目里干活的搭子:你让它先看、先想、先查,它就先收起锤子;你让它开始动手,它也真会去改文件、跑命令、看结果,而不是只会一本正经地输出“理论上可行”。
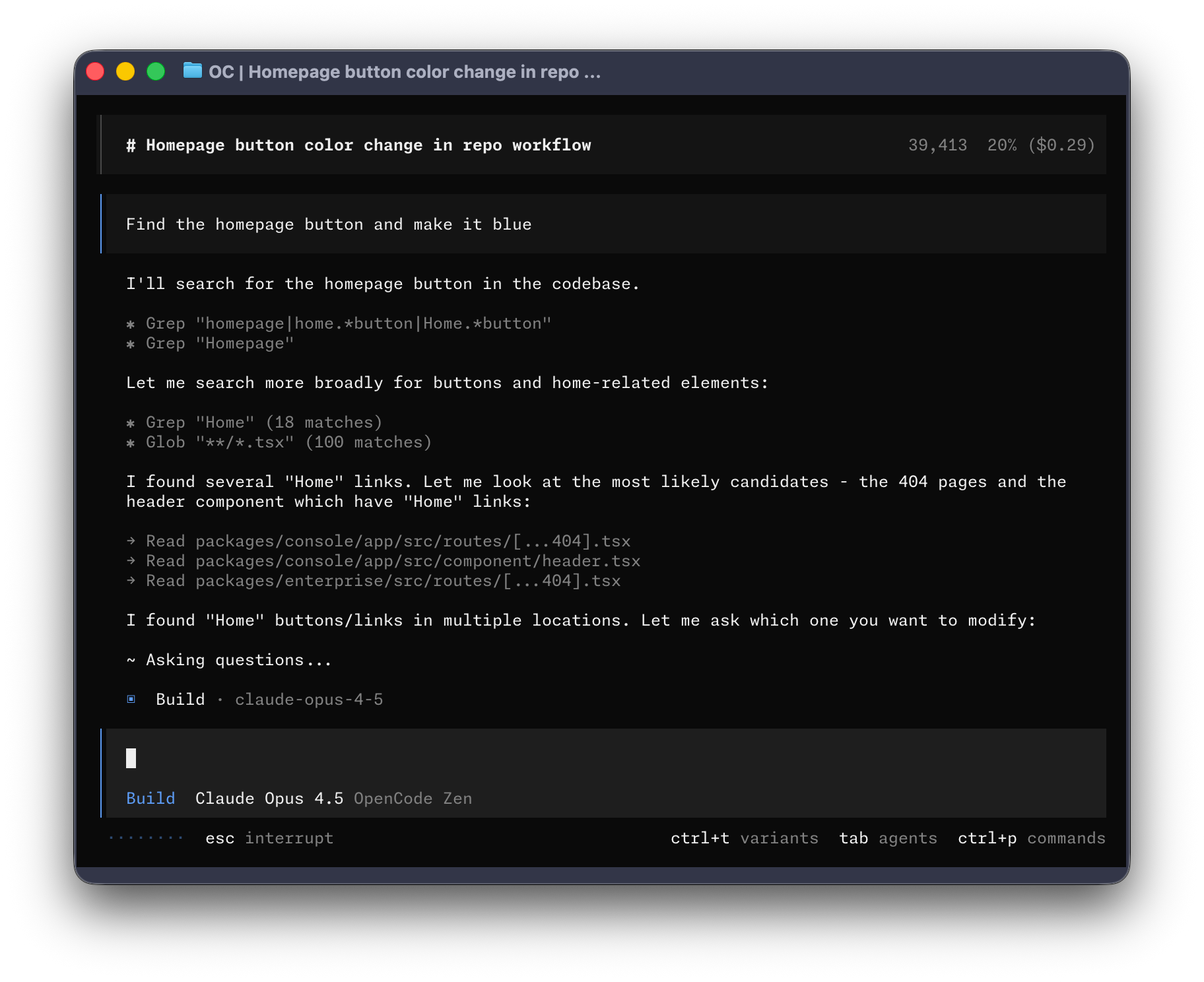
图:OpenCode 官方文档里的终端界面截图。它看起来像聊天窗口,但干起活来更像一个住在终端里的协作者。
为什么我会开始用 OpenCode
我最后把 OpenCode 留下来,不是因为它名字够响,也不是因为“AI + 终端”这几个字凑在一起显得很赛博,而是因为它刚好戳中了我日常工作流里几个很实际的点。
1. 它是开源的,而且不把你绑死在单一模型上
这点对我很重要。很多工具一上来就默认你得跟某个模型、某个平台、某个付费方案绑定终身,像办手机卡一样,一不小心就签了“靓号合约”。
OpenCode 不是这条路子。官方文档和 README 都明确提到,它可以接 Claude、OpenAI、Gemini,甚至本地模型;如果你不想折腾 provider,也可以直接用官方推荐的 Zen。
换句话说,它更像一个“调度层”,而不是“把你圈进来以后就别想跑”的入口。
2. 它真的把终端当第一现场,而不是备用停车位
这一点用久了很明显。OpenCode 默认就是 TUI 形态,命令行、会话、子代理、日志、工具调用,这些东西不是“顺手做了一个终端版本”,而是从一开始就在为终端场景设计。
如果你平时本来就长期待在 Tmux、SSH、Neovim 这套环境里,这种体验会非常顺。你不用在浏览器、编辑器插件和命令行之间来回穿梭,少掉很多上下文切换。
3. 它有很清楚的“先想再做”分工
OpenCode 内置了两个 primary agent:build 和 plan。官方文档里写得很清楚,build 默认是全工具可用,plan 则是受限模式,改文件和跑 bash 都会先问。
这个设计最值钱的地方,不是术语酷炫,而是它天然鼓励你先想清楚。很多时候不是模型不够强,而是人自己先把“分析”和“施工”搅成一锅粥,最后 AI 一边查资料一边拆墙,现场难免有点混乱。
OpenCode 至少在交互层面上,把这件事拎清楚了。
它大概适合谁
如果你是下面这种使用习惯,OpenCode 大概率会比较对胃口:
- 长时间待在终端里工作,不想再把 AI 能力单独关进浏览器标签页。
- 希望 AI 不只是补全几行代码,而是能读项目、跑命令、做多步任务。
- 想自己控制模型来源和配置,不想完全被单一平台绑住。
- 愿意把项目规范、命令习惯、目录结构写清楚,让 AI 真的学会你的工作方式。
如果你只想要“打两个字母,后面自动补完一行代码”,那编辑器里的补全插件已经够用了。OpenCode 更适合那种“帮我先看清楚,再一起动手”的场景。
安装其实不难,难的是别把第一步走歪
官方最直接的安装方式是:
curl -fsSL https://opencode.ai/install | bash
如果你不喜欢一把梭脚本,也可以用包管理器:
# Node.js
npm install -g opencode-ai
# Homebrew(官方推荐 tap,更新更快)
brew install anomalyco/tap/opencode
# Arch Linux
paru -S opencode-bin
我自己更偏向用包管理器装。原因很简单:后面升级、排错、迁移机器的时候,包管理器通常比“我当时好像 curl 过一个什么脚本”更好回忆。
官方文档对这件事说得很直接:Windows 上最佳体验优先推荐 WSL。不是 Windows 不行,而是你真把终端工具链拉到 WSL 里,后面很多细节都会少一点拧巴。
第一次用,建议按这个顺序来
1. 先进项目,再启动 OpenCode
cd /path/to/your/project
opencode
这里有个很容易敲错的小细节:/connect、/init 这些是 OpenCode 交互界面里的 slash command,不是 shell 里直接敲的 opencode /connect。
也就是说,更自然的流程是:先 opencode 进 TUI,再输入命令。
2. 先连模型或 provider
在 TUI 里执行:
/connect
如果你更喜欢纯命令行方式,也可以直接用:
opencode auth login
官方文档里还提到,认证信息通常会存到 ~/.local/share/opencode/auth.json。这点挺好,因为路径很明确,真要排查“到底有没有登录成功”,不用靠玄学。
3. 在项目里执行 /init
/init
这一步会让 OpenCode 分析项目,然后在仓库根目录生成一个 AGENTS.md 文件。
这个文件我很建议保留并提交到 Git。因为它本质上就是“给 AI 的项目说明书”:目录怎么组织、哪些命令能跑、哪些约束不能碰、测试怎么做、代码风格是什么。你写得越清楚,后面它越像一个熟悉项目的同事;你什么都不写,它就更像一个热情很高但对现场不够熟的实习生。
我现在主要怎么用它
1. 先用 plan,别急着让它抡锤子
OpenCode 官方文档明确写了,Tab 可以在 primary agent 之间切换。最常见的就是在 build 和 plan 之间来回切。
我自己的习惯是:
- 先切到
plan - 让它梳理需求、找文件、列修改点
- 确认路线没有跑偏
- 再切回
build开始施工
这套流程的好处非常朴素:减少“改了一堆,但改的不是你要的东西”。
2. 简单任务直接 opencode run
如果只是一个不需要完整进入 TUI 的小问题,官方 CLI 还提供了 run:
opencode run "Explain how closures work in JavaScript"
或者更贴近日常一点:
opencode run "帮我看一下这个仓库里为什么 sidebar 没有显示新页面"
这个模式很适合临时问答、脚本集成,或者想快速让它做一轮分析的时候。它不像完整 TUI 那样适合长对话,但胜在启动快、动作直接。
3. 复杂搜索时,让子代理干子代理该干的活
官方 agents 文档里还提到几个内置 subagent,比如 @general 和 @explore。前者更适合多步任务,后者更像只读探索员,适合快速找文件和查模式。
这个思路我很喜欢。你不必每次都自己手工指挥到“先 grep 再 read 再总结”,而是可以把某一段探索工作直接交给更合适的 agent。说白了,就是别让主力工种顺手去兼职搬砖,分工明确一点,效率会高很多。
结合我自己现在的配置,OpenCode 为什么更顺手
我自己机器上现在确实已经有一套 OpenCode 配置,主要在这两个位置:
~/.config/opencode~/.local/share/opencode
前者更像“你怎么指挥它”,后者更像“它干活之后留下什么痕迹”。
~/.config/opencode 里,我现在主要放了什么
我这边的全局配置目录下,至少有这几个文件:
opencode.jsonoh-my-opencode.json
其中 opencode.json 里,我现在配了两个比较关键的东西:
- 插件:
oh-my-opencode@latest和superpowers - 自定义 provider:
n1n
大概长这样:
{
"$schema": "https://opencode.ai/config.json",
"plugin": [
"oh-my-opencode@latest",
"superpowers@git+https://github.com/obra/superpowers.git"
],
"provider": {
"n1n": {
"npm": "@ai-sdk/openai-compatible",
"name": "n1n"
}
}
}
这套配置最能说明的一点就是:OpenCode 本身确实很适合继续往下折腾。它不是装完就只有一个固定人格、一个固定模型、一个固定玩法;你可以继续接 provider、加插件、拆 agent。
另外官方 config 文档里还明确提到,配置是会按层级合并的,而不是后面的把前面的整份覆盖掉。常见顺序包括:
~/.config/opencode/opencode.json这种全局配置- 项目根目录的
opencode.json - 项目里的
.opencode/目录
这个设计很实用。全局放通用偏好,项目里放项目约束,各管各的,不容易打架。
oh-my-opencode.json 让我更愿意把它当“工作流引擎”
我现在还有一个 oh-my-opencode.json,里面能看到不少自定义 agent 和 category,比如:
sisyphusoraclelibrarianexploremetismomus
以及 visual-engineering、deep、writing 这类分类。
这件事对我的意义不是“哇好多名字好厉害”,而是 OpenCode 的玩法一下就从“一个会回答问题的 agent”,变成了“一个能调度不同角色协作的终端工作流”。
如果你平时做的事情本来就不是单线程的——一边查代码、一边查文档、一边验证输出——这种配置方式会非常顺。
~/.local/share/opencode 基本就是它的工作现场
我本机的 ~/.local/share/opencode 目录里,现在能看到这些东西:
auth.jsonopencode.dbsnapshot/tool-output/
这几个名字其实已经把它的工作方式暴露得挺明显了:
- 有认证信息
- 有会话和状态数据
- 有快照
- 有工具输出
所以 OpenCode 不是那种“回答完你一句就风一样消失”的工具。它更像一个长期工作的系统,很多操作是有状态、有上下文、有历史可追的。这个特性在认真干活时很有价值,尤其是你需要回头看它到底改过什么、查过什么的时候。
如果你准备长期用 OpenCode,早点把全局配置、项目配置和数据目录这三件事分清楚。这样后面不管是迁移机器、排查问题,还是复用工作流,都会轻松很多。
建议先掌握这几个最小动作
如果你第一次接触 OpenCode,我不建议一上来就把 agent、插件、MCP、权限、server 这些全啃了。那样很容易在“功能真多”和“我现在到底该按哪个键”之间反复横跳。
更实际的顺序是:
第一步:先跑起来
- 安装 OpenCode
- 进入项目执行
opencode - 用
/connect配好 provider
第二步:让它认识你的项目
- 在项目里执行
/init - 把生成的
AGENTS.md看一遍 - 按你的项目习惯补充里面的规则和命令
第三步:先学会 plan/build 切换
Tab在plan和build之间切换- 先计划,再施工
第四步:最后再折腾配置
- 看
~/.config/opencode/opencode.json - 再决定要不要加插件、换 provider、拆 agent
- 需要项目级配置时,在仓库根目录加
opencode.json或.opencode/
这个顺序最大的好处是:你先得到稳定可用的体验,再慢慢把它打磨成适合自己的形状,而不是第一天就掉进“先把工作流配置到宇宙最强”这个经典深坑。
可以顺手收藏的官方页面
最后一句
OpenCode 最让我愿意长期用的地方,不是“它很聪明”,而是“它很像一个可以被你慢慢驯熟的终端工作伙伴”。
你可以先只拿它做问答,再让它帮你读代码;先让它写计划,再让它动手改;先用默认配置,后面再慢慢接 provider、加插件、拆 agent。它不像那种一上来就逼你全盘接受整套世界观的工具,更像一个允许你逐步把工作流长出来的平台。
说得接地气一点:它不是来抢你键盘的,它是来帮你少敲一点废话的。